Lei Feng Network (search "Lei Feng Net" public concern) by: This article was reprinted from Nvidia NVIDIA Enterprise Solutions public number. Zhao Kaiyong, PhD Candidate, Department of Computer Science, Hong Kong Baptist University, has long been engaged in the field of high-performance computing. He has many years of research experience in the heterogeneous computing of CPUs and GPUs. Mr. Zhao Kaiyong has participated in the research and development of high-performance projects in several research institutes and high-performance users. He has served as Inspur GPU high-performance computing consultant and has served as the judge of the NVidia China CUDA Competition. He also organized the publication of "CUDA for GPU High Performance Computing" and translated the second edition of "The Massive Parallel Processor Programming Battle." One of the earliest researchers to promote GPU high performance computing in China.
One of the hottest words in the field of artificial intelligence is Deep Learning (DL). In recent years, deep learning has become the absolute mainstream of visual computing in academia and even in the entire industry. In addition to the traditional computer geometry processing, professional rendering, medical, life sciences, energy, financial services, automotive, manufacturing, and entertainment industries, one has to focus on deep learning applications and technological optimization to avoid losing in the corporate competition. GPUs play a crucial role in the competition for technology, and related technology optimization is also one of the focuses of researchers.
"Deep learning technology can already be used to solve practical problems, rather than staying in Demo stage."
Such as Microsoft's speech translation, Google's cat identification, to the recent very face recognition, as well as automatic driving, etc., these are typical applications of deep learning. Big companies such as Alibaba, Baidu, Facebook, Google and IBM all have great investments in DL. Here, we must emphasize that at present, many mainstream DL frameworks and algorithms are basically developed by the Chinese. The revival of the DL cannot be separated from Chinese researchers.
"Two things you need to consider before conducting deep learning training"
One is a software framework such as Caffe, Tensorflow, Mxnet, and so on.
The other is hardware. In terms of hardware, there are many heterogeneous forms, such as cpu, fpga, dsp, etc., but the most popular is the GPU. It is also CUDA hardware (NVIDIA GPU) + CUDA DL learning software (cuDNN) that can really quickly create combat power in DL. ) This is the result of NVIDIA's years of research and development.
If a worker wants to do good, he must first sharpen his tools.
Now the mainstream DL development training platform generally uses NVIDIA graphics cards. For example, the NVIDIA TITAN series is a very good tool. In order to speed up the training, generally choose to train on high-performance computers or clusters equipped with multiple GPUs. The trained network can also be easily ported to embedded platforms with NVIDIA Tegra processors, such as NVIDIA Jetson TX1, which have the same The architecture, so it will be very convenient to transplant.
Based on the NVIDIA Tegra X1 processor, the Jetson TX1 uses the same Maxwell architecture 256-core GPU as the supercomputer, providing up to 1T-Flops of computing performance and full support for CUDA (Compute Unified Device Architecture) technology, with pre-installed development The tool is ideal for the creation of smart embedded devices based on deep learning. Not too long ago, users used the Jetson platform equipped with a Tegra processor to check if there were kittens in their own gardens.
The highlight: Convolutional neural network CNN algorithm optimization
The video that detects cats dropping into the garden is popular in the Internet. This application uses the classification of the Convolutional Neural Network (CNN) to learn on desktops or clusters and then porting them to Tegra. The CNN algorithm plays a key role. The most critical part of CNN is the convolution layer. In the field of image recognition and image classification, the main reason why CNN can work is that the key is convolution. It evolved from two aspects. One is a delay network for sound processing and the other is a feature extraction algorithm for image processing. For the latter, the convolution is to filter the image. In simple terms, it is to do some feature extraction. Common sobel edge extraction, as well as hog, Gaussian filtering and so on, these are two-dimensional convolution.
Convolution shape optimization
Although everyone is now doing convolutions are square, but in fact this is only a definition, you can not follow this standard, you can use other shapes instead of convolution, to better adapt to your calculations, especially the convolution kernel When larger, this is also a way to optimize the convolution. In general, the current popular CNN network, the convolution part will occupy more than 70% of the computing time, optimization of the convolution part is very necessary. You need to take into consideration many aspects, such as algorithmic aspects, parallelism, and GPU hardware features. The GPU itself is a programmable parallel computing architecture. It has a lot of good algorithms. At the same time, NVIDIA also provides corresponding tools to help you optimize.
The basic idea of ​​convolution optimization
1. Compute in parallel
2. Data parallelism
3. Parallel granularity
4. Space change time
5. IO and Compute Overlays
6. More efficient use of cache space
7. For the parallel characteristics of the hardware, more efficient use of the network and hairstyle
Use memory to change time
If the convolution of each layer in the deep learning DL is for the same picture, then all the convolution kernels can convolute the picture together and then store them in different locations. This can increase the memory. Use rate, load the picture one time, produce multiple data, do not need to visit the picture many times, this is to use memory to exchange time.
Multiplication optimization
Convolution is a multiplication of a small area, and then add, which is very mature in the field of parallel computing.
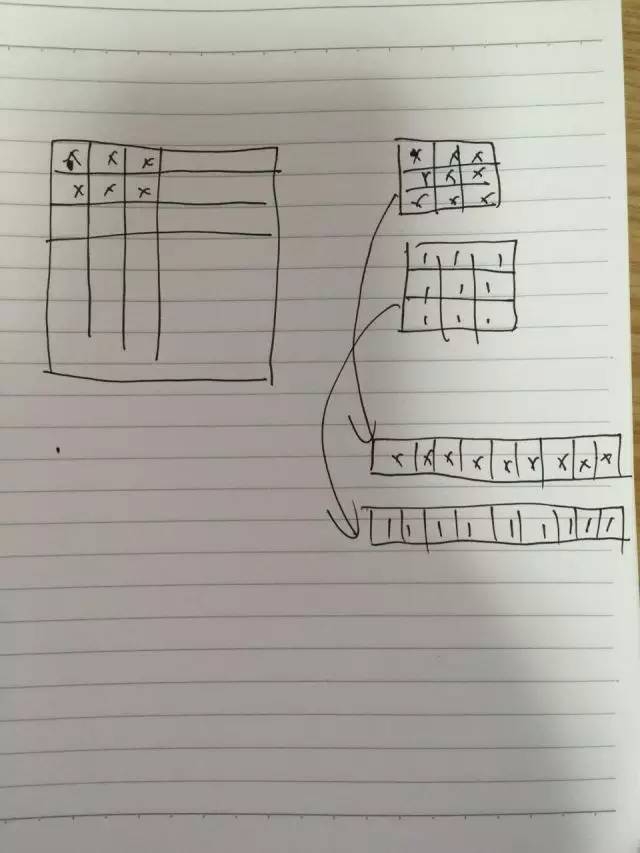
For example, the above picture shows a picture on the left and a convolution kernel on the right. We can transform the convolution kernel into a single row, then multiple convolution kernels can be arranged into multiple rows, and then the image can be expanded in a similar way. This can convert a convolution problem into a multiplicative problem. This is a multiplication of a row by a column, which is a result. Although this has done some unfolding operations, the speed will increase a lot for computing.
Several ideas for GPU optimization
Understand IO access and IO performance;
Multithreaded parallel computing features;
Overlapping computing time between IO and parallel computing
For NVIDIA's GPUs, memory access has a number of features. Continuous merge access can make good use of the hardware's bandwidth. As you can see, NVIDIA's latest architecture of GPUs may not have a significant increase in the number of cores, and the architecture does not seem to change much. However, adding caches among several compute stream processors will increase the performance greatly. Visiting this piece has brought great optimization.
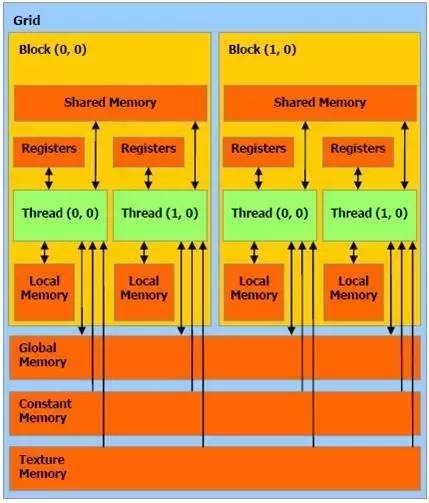
The above is a more classic memory and thread model, shared memory and registers are the fastest memory access, memory access compared with the calculation, too slow, so try to put more data into the high-speed cache.
Several Ideas of Matrix Optimization
From a calculation point of view
From the results
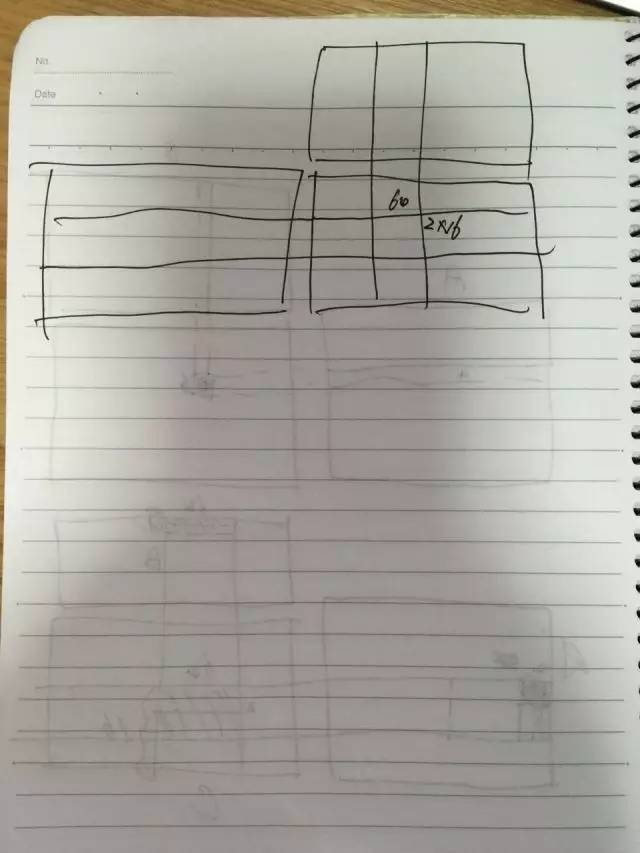
Taking the above image as an example, when we start from the results of the C matrix, each C needs one row of A and one column of B to perform the calculation. Using the characteristics of the GPU, we can store the zero-hour result in the registers surface. We can divide the 64x2 threads as computational threads.

In the photocopying part of C, there can be 64×2 so many threads in one visit, and 64×2 data can be stored. You can store 64 or 2 data per thread for 64 x 2 threads. Then we can store 64 x 2 x 16 (32) data with 64 x 2 threads. Such multiple data can be stored in the fastest memory at a time. When reading and writing many times, the speed can be very fast. At the same time, we are considering the access to the A and B matrices. We can put the corresponding data of the B matrix into the shared memory, which improves the shared memory utility. In this way, the whole A×B can be merged and accessed according to these threads when reading the global memory (A matrix), and the merge access can be accelerated according to the read of each row 32, 32 . This sorts out the entire matrix optimization idea.
These are some optimization ideas for deep learning convolution on the GPU and even on the Jetson TX1 platform.