Last weekend, one of the most influential scientists in the field of artificial intelligence, Li Feifei—a tenured professor at Stanford University and chief scientist at Google Cloud—delivered a fascinating talk titled “Visual Intelligence Beyond ImageNet†at the Future Forum. She highlighted how AI has evolved beyond just identifying objects; it can now understand the content of images, generate short descriptions based on visual input, and even interpret videos with increasing accuracy.
Speech by Li Feifei
Final Translation
Today, I'd like to share some of our recent research directions focused on visual intelligence. Vision is not only a fundamental sense for humans but also a critical component for machine learning systems. With over 500 million years of evolution, the human visual system has become highly sophisticated, with nearly half of the brain’s cortex dedicated to processing visual information. This emphasizes the importance of vision in both biological and artificial systems.

The Cambrian explosion marked a significant evolutionary milestone, and since then, our ability to perceive and interpret the world through sight has been crucial for survival. Cognitive experiments have shown that humans can recognize people in images presented for as little as 1/10th of a second, demonstrating the speed and accuracy of our visual system.
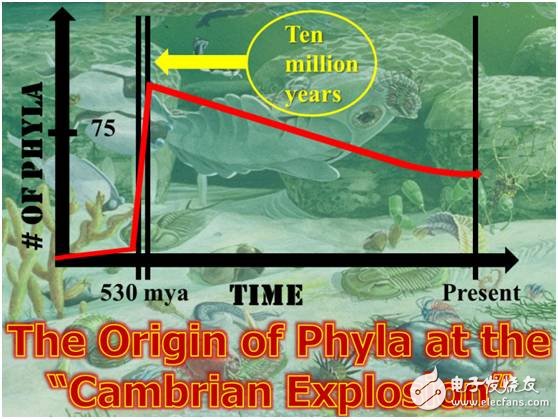
Cambrian species outbreaks Source: genesispark.com
In 1996, Simon J. Thorpe's groundbreaking research showed that humans can distinguish complex images within 150 milliseconds. This discovery inspired computer scientists to focus on image recognition, leading to major breakthroughs like convolutional neural networks and GPU technology. Today, computers have made remarkable progress in this area, reducing error rates by 10 times in just eight years.
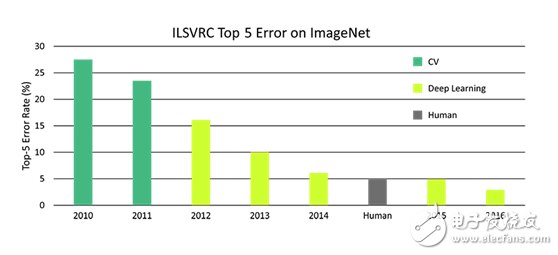
In the 8 years of the ImageNet Challenge, the error rate of computer classification of images was reduced by 10 times. Image source: dsiac.org
Beyond simple object recognition, we are now exploring more complex tasks such as understanding relationships between objects in an image. For example, two images may contain similar objects, but the context or story they tell can be entirely different. Our goal is to enable machines to grasp these relationships, which is a key step toward true visual intelligence.

We're using deep learning and visual language models to help computers understand spatial relationships, compare objects, detect symmetry, and even interpret actions and prepositions. This allows for a richer, more nuanced understanding of visual scenes than just identifying individual objects.

Visual Relationship Detection with Language Priors. ECCV. 2016
More intriguingly, we've developed algorithms that can perform zero-shot learning, where a model can recognize object relationships without prior exposure to specific examples. For instance, if trained on images of "a person sitting on a chair" and "a fire hydrant next to a person," the model can later recognize "a person sitting on a fire hydrant" without seeing that exact combination before.
Let AI Read the Image
As object recognition becomes more accurate, the next challenge is to understand the broader context—relationships, language, and meaning. While ImageNet provides valuable data, it's limited in capturing the full richness of visual information. To address this, we created the Visual Genome dataset, containing over 100,000 images, 1 million attributes, and millions of questions and answers, enabling more detailed analysis of visual relationships.
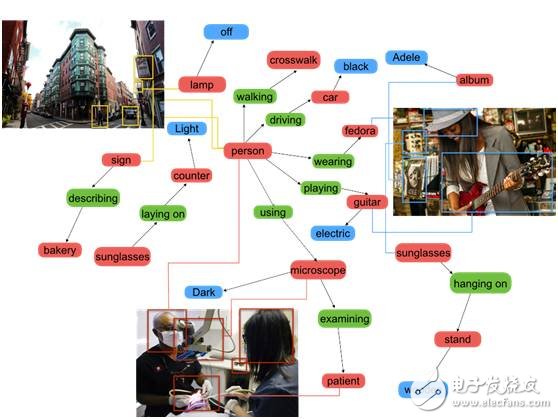
Image source: Visualgenome.org
Using tools like scene graphs, we can go beyond simple object detection and explore more complex interactions. For example, searching for "a man in a suit holding a cute puppy" is more challenging than searching for "man in a suit" or "cute puppy." Our new algorithms significantly improve search accuracy by considering object relationships and context.
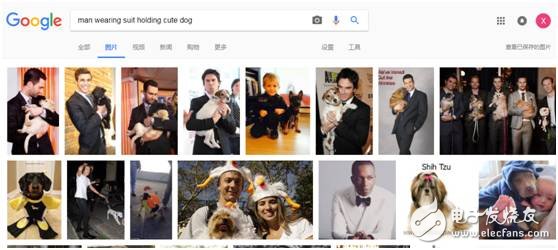
Xiaobian tried it today (November 1, 2017), and the accuracy of Google Images has improved dramatically.
But how do we build such datasets? Currently, scene graphs are manually created, which is time-consuming and labor-intensive. Our next step is to develop automated techniques for generating scene graphs, allowing machines to analyze images independently.
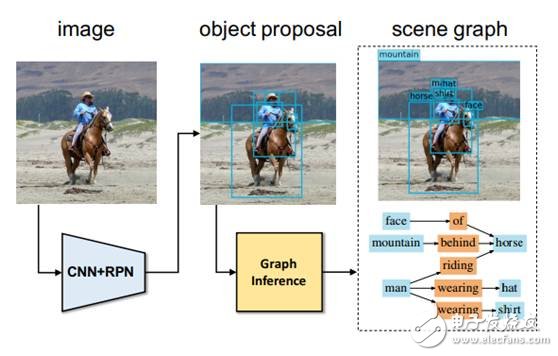
Scene Graph Generation by Iterative Message Passing. CVPR. 2017
Can artificial intelligence understand videos like humans?
While the Visual Genome dataset improves machine understanding of static images, video presents a new challenge. We're working on algorithms that can capture dynamic scenes, describe them in detail, and even generate paragraphs that reflect the complexity of real-world events.
Combining Visual Cognition with Logical Reasoning
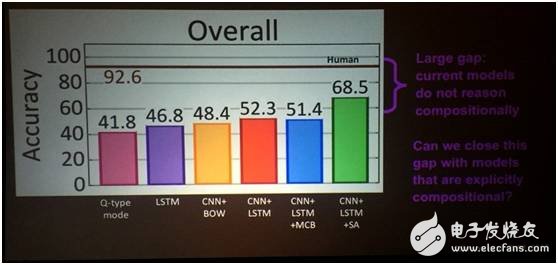
Finally, we’re exploring how AI can go beyond perception and perform task-driven reasoning. By combining visual input with language, we aim to create systems that can answer complex questions, count objects, and make logical decisions based on visual cues. This is a growing field, and while humans achieve over 90% accuracy in reasoning tasks, machines still lag behind, showing the need for further innovation.
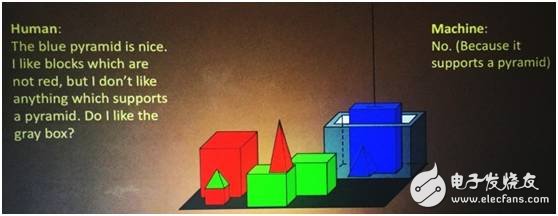
Our work with Facebook on the Clever dataset highlights the gap between human and machine reasoning. Although AI can achieve up to 70% accuracy, there's still room for improvement, especially when it comes to combining visual and logical reasoning.
To bridge this gap, we're developing execution engines that break down problems into manageable blocks, allowing machines to reason about real-world scenarios more effectively. This approach has already shown promising results in tasks like shape identification and object counting.

In summary, our work goes beyond ImageNet by focusing on relationship recognition, semantic understanding, and task-driven reasoning. As visual intelligence continues to evolve, the integration of vision and logic will play a crucial role in shaping the future of AI.

Our firm introduced whole set of good-sized numerical control hydraulic folding equipment(1280/16000) as well as equipped with a series of good-sized professional equipments of armor plate-flatted machine, lengthways cut machine, numerical control cut machine, auto-closed up machine, auto-arc-weld machine, hydraulic redressing straight machine, etc. The firm produces all sorts of conical, pyramidal, cylindrical steel poles with production range of dia 50mm-2250mm, thickness 1mm-25mm, once taking shape 16000mm long, and large-scale steel components. The firm also is equipped with a multicolor-spayed pipelining. At the meantime, for better service to the clients, our firm founded a branch com. The Yixing Jinlei Lighting Installation Com, which offers clients a succession of service from design to manufacture and fixing.
We have supplied 2400ton 132kV and 220kV transmission line steel pole to WAPDA. Pakistan on 2008 and have supplied 1200ton 138kV transmission line steel pole to Davao light, Philippines on 2009.
Street Lighting Pole, Solar Power, Solar Lighting Pole
JIANGSU XINJINLEI STEEL INDUSTRY CO.,LTD , https://www.steel-pole.com